

【不吐不快】关于Cloudflare于11.18故障的解读
互联网的“蝴蝶效应”:Cloudflare 史诗级宕机事件深度复盘
事件背景:2025 年 11 月 18 日,全球互联网基础设施巨头 Cloudflare(下文简称 CF)遭遇严重故障,导致海量核心网络流量无法正常传输。一次看似普通的权限更新,意外触发了历史代码的隐藏漏洞,最终酿成了一场波及全球的断网事故。
1. 故障表现与排查时间线 (UTC)
当故障发生时,尝试访问托管在 CF 上网站的用户,都会面临一个冰冷的错误页面,提示 CF 网络出现故障。
⏳ 核心时间线还原:
| 时间 (2025.11.18) | 事件节点 | 详细状态与工程师反应 |
|---|---|---|
| 11:05 | 埋下隐患 | 工程师推送了一项数据库“权限设置”更新,旨在优化查询效率。 |
| 11:28 | 故障爆发 | “机器人管理 (BM)” 模块拿到错误数据后发生崩溃,请求大面积失败。 |
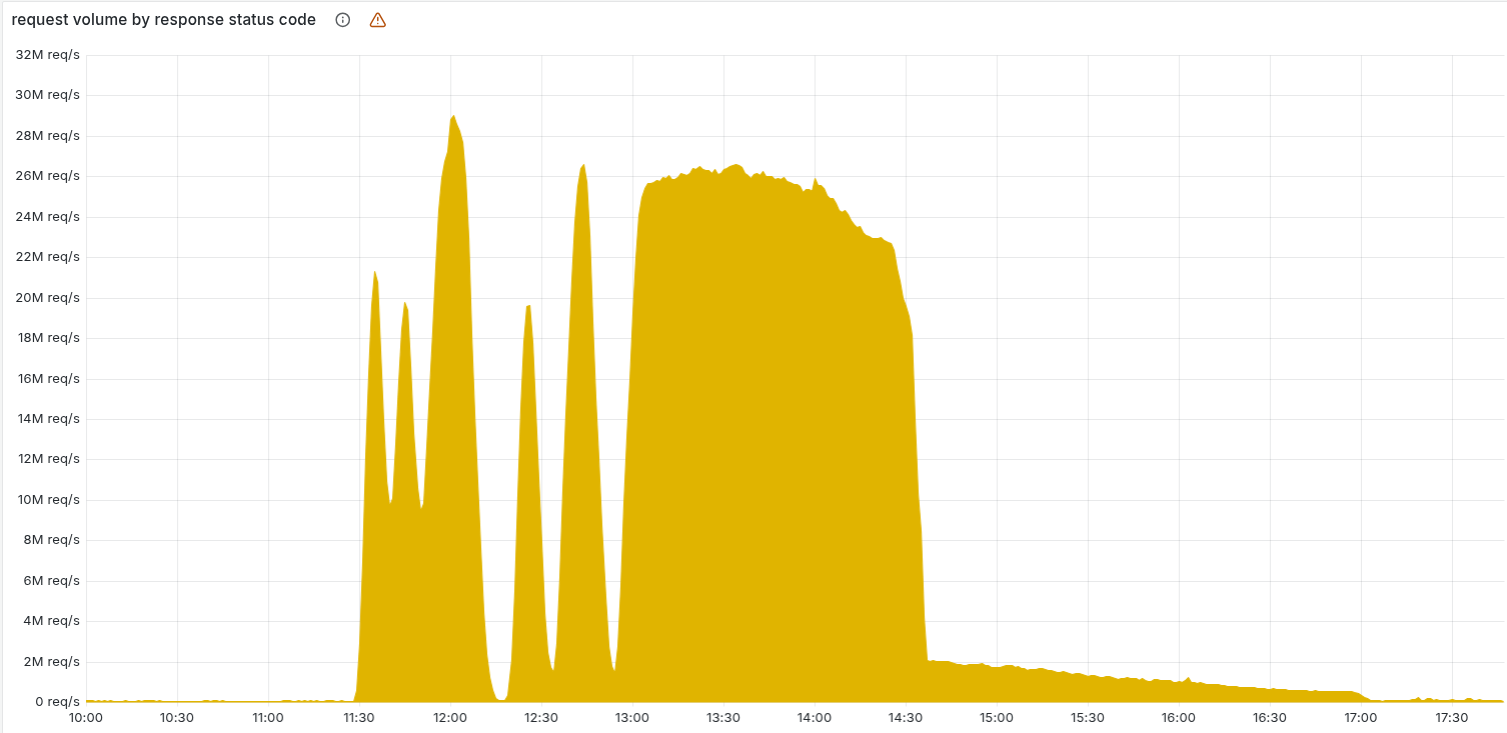
| 前两小时 | 陷入误区 | 报错曲线呈“过山车”式的剧烈震荡(因节点逐步更新)。工程师误以为遭到了 DDoS 攻击。 |
| 13:30 | 定位方向 | 所有机器更新完毕,报错曲线变成“平稳的直线”。工程师意识到是内部系统故障。 |
| 14:24 | 根源锁定与修复 | 查明 SQL 代码与权限的冲突。切断 BM 模块自动更新,手动部署干净数据,服务逐步恢复。 |
2. 致命的“连环翻车”:技术起因深度拆解
简单来说,这是一个 “好心的权限更新” 遇到了 “历史遗留的 SQL 漏洞”,并在 “特定数据库机制” 的推波助澜下,最终引爆了 “程序底层的硬编码雷区” 的经典事故。
环节一:历史包袱与“好心”的权限更新
CF 的“机器人管理”(BM) 模块需要读取特征列表(如 IP、浏览器类型等)来拦截爬虫。
- 历史笨办法:受限于早期的权限架构,程序必须分两步走:先去
defaultdatabase拿到“列名清单”(元数据),再拿着清单去R0数据库提取真实数据。 - 致命更新 (11:05):为了提高效率,工程师推送了一个更新,允许 BM 模块直接读取
R0数据库的元数据。本意是想跳过第一步,让程序跑得更快。
环节二:模糊的 SQL 代码遇上 ClickHouse 机制
- 有漏洞的 SQL:负责获取清单的 SQL 代码写得非常“模糊”——它只要求查询
http_request_features这张表的列名,却隐瞒了(没有明确指定)要去哪一个数据库里查。 - ClickHouse 的“隐性权限”陷阱:与传统的 PostgreSQL(连哪个库就只看哪个库)不同,CF 使用的 ClickHouse 数据库是基于权限视图的。只要你有权限,一个模糊查询就能扫遍所有数据库。
- 灾难合并:权限更新后,这段模糊的 SQL 同时在
defaultdatabase和R0里都找到了清单。ClickHouse 将这两份清单合并返回,导致程序拿到了一份体积翻倍的“重复列表”。
环节三:Rust 的“大杀器”与傲慢的“200”
- 固定长度的数组:CF 的程序员曾自信地认为,特征数据绝对不可能超过 200 项。为了极致的运行速度,他们用 Rust 语言写死了一个“固定长度为 200”的内存空间(盒子)来装这个列表。
- 系统崩溃 (
unwrap):当体积翻倍的错误列表(超过 200 项)试图硬塞进这个盒子时,内存溢出报警。偏偏程序里使用了 Rust 语言中的大杀器——unwrap指令。它的逻辑非常暴力:一旦遇到意外错误,不作任何周旋,立刻让整个程序“崩溃”停掉。
3. 总结与反思
“在这个时代,支撑全球运转的互联网基础设施,远比我们想象的要脆弱。”
这次史诗级宕机的表面原因是逻辑冲突,但根源却是程序员为了“图方便”走捷径所留下的技术债(Technical Debt):
- 写了指向不明的 SQL 代码(缺乏严谨的边界限定)。
- 使用了硬编码的固定长度数组(缺乏对未来数据增长的敬畏心)。
- 滥用直接崩溃的错误处理机制(缺乏优雅降级的容灾方案)。
同时,这也给行业敲响了警钟:当全球算力和网络流量越来越高度集中在 CF、AWS、Google 等少数几家大厂手中时,一个极其低级的代码失误,就足以让半个互联网瞬间停摆。
原稿:
一、情况呈现
2025 年 11 月 18 日 11:20 UTC,CF(Cloudflare,下文均简称CF) 的网络开始出现严重故障,无法正常传输核心网络流量。尝试访问的用户会看到一个错误页面,提示 CF 网络出现故障。
二、起因
一个权限更新 CF 有一个叫做“机器人管理”(Bot Management, BM)的模块,专门用来检测访问网站的是真人还是爬虫程序 。这个模块需要定时从数据库获取最新的数据来更新自己 。在11点05分,一位程序员推送了一个数据库的“权限设置”更新。
这个权限更新本身没问题,但它和一段有漏洞的 SQL 查询代码(从数据库拿数据的指令)产生了冲突。
CF 用的是一个叫 ClickHouse 的特殊数据库 。在这个数据库上,新的权限导致那段有漏洞的代码从两个地方同时拿到了数据,结果就是拿到了一份“重复”的数据列表。
这个列表本应只有不到200项,但重复后就超出了200项。PS:这个200纯粹是因为CF的程序员觉得features(数据表中的数据)到不了200项
BM 模块的程序(用 Rust 语言写的)为了追求速度,提前设定好了一个“固定长度为200”(即为上文的200项)的内存空间来装这个列表 。
当程序试图把这份“超长”的重复列表塞进这个只能装200个的“盒子”时,就发生了错误 。
程序中用了一个叫 unwrap (Rust的大杀器)的指令,它的作用是:一旦遇到这种严重错误,就立刻让整个程序“崩溃”停掉。
于是,在11点28分,BM 模块一拿到错误数据就崩溃了,导致所有通过它访问网站的请求全部失败。
一开始,这个故障时好时坏,因为数据库更新是逐步推送的,有的机器崩溃了,有的还没 。
这种“过山车”式的报错曲线,让工程师在头两个小时里一直以为是遭到了黑客攻击(DDoS)。
直到13点30分,所有机器都更新了,故障变成了一条“平稳的直线”,工程师才意识到是内部系统出了问题。
三、解决
工程师们最终在14点24分找到了问题的根源(那段 SQL 代码和权限问题),他们先切断了 BM 模块的自动更新功能,然后手动部署了一份干净的数据,服务才开始慢慢恢复。
四、总结
这次故障的根源,其实是程序员为了“图方便”走捷径(写了有漏洞的SQL代码、使用了固定长度的数组)导致的低级错误 。视频认为,这反映出我们现在依赖的整个互联网其实非常“脆弱” ,它建立在各种追求方便的“快捷方式”之上,并且高度集中在少数几家大公司(如 CF, AWS, Google)手中。
五、起因中数据库冲突细致讲解
简单来说,这是一个“好心的权限更新”遇到了一个“有历史遗留漏洞的代码”的经典事故,而火上浇油的是它们所使用的一个特定数据库(ClickHouse)的独特工作方式。
1.历史原因
Cloudflare 的“机器人管理”(BM) 模块需要一个“特征列表”(比如IP地址、浏览器类型等)来判断是不是机器人。
这个列表信息存储在数据库 R0 中。
但由于某些历史原因,程序不能直接去 R0 拿这个列表。它必须分两步走:
-
先去一个叫 defaultdatabase 的数据库,问它:“R0 里的那个特征列表,它都包含哪些列?(即获取元数据)”
-
拿到这个“列名清单”后,再拿着清单去 R0 数据库说:“好了,按照这个清单,把数据给我。”
2.权限更新
在11点05分,工程师推送了一个更新,目的就是为了解决上面那个“笨办法”。
这个更新的作用是:“允许 BM 模块直接读取 R0 数据库的元数据(列名清单)”。
这样一来,程序以后就可以跳过第一步,直接在 R0 里完成所有操作,更简单、更高效。
3.SQL 代码
问题出在第一步(去 defaultdatabase 拿清单)的那段查询代码(SQL)上。
那段代码写得很“模糊”,它大致的意思是:“请在 system.columns 表里,把 http_request_features 这张表的所有列名都给我。”
它致命的缺陷是:它只说了要查哪张表,但没有明确说要去“哪一个数据库”里查。
4.ClickHouse 数据库的独特机制
Cloudflare 用的 ClickHouse 数据库,它的一种工作机制和我们常见的数据库(如 PostgreSQL)不一样:
普通数据库:你连接哪个数据库,就只能看到哪个数据库里的东西。
ClickHouse:它的查询权限是“隐性”的。一个查询会看到所有它有权限访问的数据库里的数据。
5.连锁反应
结果,它在 defaultdatabase 里找到了清单(第1份),又在 R0 里也找到了清单(第2份)。
最终,它把两份清单合并成一份,返回给了程序。
所以,程序(BM 模块)拿到的不再是正常的列表,而是一份所有项目都重复了一遍的“加倍列表”。